In this note series on Probability and Statistical Inference, we have seen Probability Theory basics. To model and solve the random phenomenons, we will use the basic concepts of Probability Theory and other modeling techniques that we will cover in the current and subsequence notes.
Whenever we perform certain experiments, we have observations, and these observations can be in the form of discrete (1,2,3,4, etc.) or continuous (1.11,1.211, 1.2, etc.) data. To represent the data, we need a certain concept, and that concept is called a random variable.
In this note, we introduce the random variables, types of random variables, and techniques to study the characteristics of a random variable with the help of a distribution function and various types of moments. Before deep-diving into these important topics, we will understand the need for random variables, experiment setup, and the criteria for selecting a type of random variable.
Need for Random Variable
Suppose we know the starting salary of a sample of 100 students graduating in statistics. So learning the parameters from the sample data, we can conclude the expected salary for the population of all students graduating in statistics.
Similarly, suppose a newly developed drug is given to a sample of selected Covid patients, some patients may show improvement, and some may not. However, we are interested in the consequences for the entire population of patients.
To draw such conclusions, we need some concepts that are essential to draw statistical conclusions from a sample of data about a population of interest.
Random variables are the foundation of the theoretical concepts required for making such conclusions. They form the basis for statistical tests and inference.
Example 1:
Suppose our experimental setup is tossing a coin. The possible outcomes are head and tail.
- The sample space is
which tells what are all the possible outcomes. In this case, possible outcomes are:
. In this case, it is easy to answer the probability of getting head or tail. However, it would be difficult to answer when somebody asks the likelihood of head after 20 tosses or more as outcomes are in the categorical forms such as head and tail, rather than numerical values.
To solve this problem for any number of tosses, we can generalize it and assign numerical values to the possible outcomes such as:

Thus X is a real valued function defined on 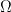
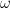
In the below python example code, whenever we run this code, it may print 0 or 1. However, on average, we can not predict the value of randint function not better than 50% accuracy.
import random print(random.randint(0,1))
In the same way, we can take the example of rolling a dice. The possible outcomes are {1,2,3,4,5,6}, and the same can be modeled using the python code as shown below.
import random print(random.randint(1,6))
In each run of the above code, we will get different values that we can’t predict on average with more than 50% accuracy.
In any random experiment, we are interested in the value of some numerical quantity determined by the result. These quantities of interest that are determined by the result of the experiment are known as random variables. Since the value of a random variable is determined by the outcome of the experiment, we may assign probabilities of its possible values. Let us consider the same coin tossing example, in which the probabilities of the outcome are:


We may therefore view X as a random variable that collects the possible outcomes of a random experiment and captures the uncertainty associated with them. In general, every random variable has its distribution based on our formulated investigation and definition of random variables.
Example 2:
Suppose we toss two dice and we want to study about the sum of the points on the upper face of two dice to be 7. In this example, we can’t consider a random variable, as it has been asked a specific question, so this specific question can be considered as an event. The favourable outcomes could be (1,6),(2,5),(3,4),(4,3),(5,2),(6,1) out of total (1,1),(1,2),(1,3),(1,4),(1,5),(1,6),(2,1),(2,2),(2,3),(2,4),(2,5),(2,6),(3,1),(3,2),(3,3),(3,4),(3,5),(3,6),(4,1),(4,2),(4,3),(4,4),(4,5),(4,6),(5,1),(5,2),(5,3),(5,4),(5,5),(5,6),(6,1),(6,2),(6,3),(6,4),(6,5),(6,6). The probability for this event is: 6/36 = 1/6.
We know that the random variables represent the quantities of interest determined by the result of the experiment. Suppose, if we want to consider a random variable for this experiment, the selection would be the sum of the points on the upper face of two dice.
The possibilities are as follows:
- P(X=2) = P{(1,1)} = 1/36
- P(X=3) = P{(1,2),(2,1)} = 2/36
- P(X=4) = P{(1,3),(2,2),(3,1)} = 3/36
- P(X=5) = P{(1,4),(2,3),(3,2),(4,1)} = 4/36
- P(X=6) = P{(1,5),(2,4),(3,3),(4,2),(5,1)} = 5/36
- P(X=7) = P{(1,6),(2,5),(3,4),(4,3),(5,2),(6,1)} = 6/36
- P(X=8) = P{(2,6),(3,5),(4,4),(5,3),(6,2)} = 5/36
- P(X=9) = P{(3,6),(4,5),(5,4),(6,3)} = 4/36
- P(X=10) = P{(4,6),(5,5),(6,4)} = 3/36
- P(X=11) = P{(5,6),(6,5)} = 2/36
- P(X=12) = P{(6,6)} = 1/36
In this case, the random variable takes a value from 2 to 12 and produces probabilities for each value.
From the above outcomes, we can tell that the probability of getting P(X=7) has the highest chance, which is 1/6 compared to other values. And another observation is that the sum of all the probabilities of each value of a random variable is equal to 1. In general, we can write as follows:

We have tried to build a background to understand the need for a random variable and how to define a random variable from an experimental point of view. In the below section, we will formally define what a random variable is and the conditions it must meet.
Random Variable
Let 

It is a convention to denote random variables by capital letters (e.g. X) and their values by small letters (e.g. x). For example, if X is height of students (random variable), the 

Discrete Random Variable
Random variables whose set of possible values can be written either as a finite sequence 
For instance, a random variable whose set of possible values is the set of nonnegative intergers is a discrete random variable.
Example 1:
- When we roll six-sided dice, the possible values are 1,2,3,4,5,6.
- When we roll two six-sided dice, the sum of the upper face of two dice is 2,3,4,5,6,7,8,9,10,11,12.
These are the values a random variable takes. In both the examples, the values are positive integers such as 1,2,3,4,5, etc., rather than 1.2, 1.3, etc.
Example 2:
A customer care phone contains 30 external lines. At a particular time, the system is observed, and some of the lines are being used.
Let the random variable X denote the number of lines in use. Then, X can assume any of the integer values 0 through 30. For instance, when 5 lines are in use then value of x = 5 and it is represented as 
Example 3:
Suppose a dimensional length is measured, such as vibrations, temperature fluctuations, calibrations, cutting tool wear, bearing wear, and raw material changes. There can be slight variations in the measurements in practice due to many causes. In an experiment like this, the measurement is represented as a random variable X. It is reasonable to model the range of possible values of X with an interval of real numbers. As a result, these values are not suitable for the discrete random variable.
So, to handle these values, there is another type of random variable called a continuous random variable.
Continuous Random Variable
A sample space is continuous if it contains an interval (either finite or infinite) of real numbers. Whereas, a sample space is discrete if it contains a finite or countable infinite set of outcomes.
For example:
When we say that it is mandatory to know 

![(\infty, s], x \in R](https://s0.wp.com/latex.php?latex=%28%5Cinfty%2C+s%5D%2C+x+%5Cin+R&bg=ffffff&fg=000&s=0&c=20201002)
![\begin{aligned}[latex]P(X \in A) &= P(X \in (-\infty, x]) \\ &= P(- \infty < X \leq x) \\ &= P(X \leq x)\end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D%5Blatex%5DP%28X+%5Cin+A%29+%26%3D+P%28X+%5Cin+%28-%5Cinfty%2C+x%5D%29+%5C%5C%C2%A0+%26%3D+P%28-+%5Cinfty+%3C+X+%5Cleq+x%29+%5C%5C+%26%3D+P%28X+%5Cleq+x%29%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)

Summary
A random variable can be discrete or continuous based on the experiment's experimental setup or sample space. In general, to find the probability of a random variable for a particular event, we denote it as 
- If a random variable is discrete, we use a method called probability mass function (PMF) to find the probabilities of discrete random variables.
- If a random variable is continuous, we use a method called probability density function (PDF) to find the probabilities of a continuous random variable.
- We use the cumulative distribution function (CDF) to get the probability of random variables in an aggregated way. The cumulative distribution function definition is different for different types of random variables.
- To characterize the random variable we compute moments with the help of PMF or PDF depending upon the random variables. The moment gives, Weighted Mean tells the central tendency of data, VARIANCE measures the spread (dispersion), SKEWNESS measures asymmetry, and KURTOSIS measures the spread as compared with a special type of distribution called a normal distribution.
References
- Essentials of Data Science With R Software – 1: Probability and Statistical Inference, By Prof. Shalabh, Dept. of Mathematics and Statistics, IIT Kanpur.
CITE THIS AS:
“Random Variables” From NotePub.io – Publish & Share Note! https://notepub.io/notes/mathematics/statistics/statistical-inference-for-data-science/random-variables/
21,241 total views, 1 views today