In the previous note on the Probability and Statistical Inference, we have learned expectations, moments, skewness, and kurtosis to measure the central tendency, dispersion, symmetry, and peakedness of probability curve or distribution, respectively.
Introduction
We define quantiles in terms of the distribution function. The value 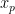 for which the cumulative distribution function is:
for which the cumulative distribution function is:

is called the p-quantile.
Here, is a value which divides the CDF into two parts: The probability of observing a value left of is p, whereas, the probability of observing a value right of is 1-p.
For example, the 0.25 quantile  describes the x-value for which the probability of observing or any smaller value is
describes the x-value for which the probability of observing or any smaller value is 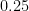 .
.

The above figure shows the 0.25-quantile (first quartile), the 0.5-quantile (median), and the 0.75-quantile (third quartile) is a cumulative distribution function.
Quantiles
Quantiles are the values that divide the distribution into different partitions. These partitions can have equal or unequal widths, so in general, these partitions are called Quantiles, and we decide the size of the partition based on the requirements. For example:
- 25% Quantile: Splits the data into two parts such that at least 25% of the values are less than or equal to quantile, and at least 75% of the values are greater than or equal to quantile.
- 50% Quantile: Splits the data into two parts such that at least 50% of the values are less than or equal to quantile, and at least 50% of the values are greater than or equal to the quantile. It is also called Median.
In general,  quantile: Value which divides the data in proportions of and
quantile: Value which divides the data in proportions of and  such that at least of the values are less than or equal to the quantile and at least of the values are greater than or equal to the quantile.
such that at least of the values are less than or equal to the quantile and at least of the values are greater than or equal to the quantile.
Quartiles
The values which divide the given data into four equal parts, say,  .
.
 : First quartile which has 25% of the observations.
: First quartile which has 25% of the observations.- : Second quartile which has 50% of the observations also called Median.
- : Third quartile which has 75% of the observations.
- : Fourth quartile which has 100% of the observations.
 : First quartile which has 25% of the observations.
: First quartile which has 25% of the observations. : Second quartile which has 50% of the observations also called Median.
: Second quartile which has 50% of the observations also called Median. : Third quartile which has 75% of the observations.
: Third quartile which has 75% of the observations. : Fourth quartile which has 100% of the observations.
: Fourth quartile which has 100% of the observations.We have divided the entire frequency distribution into four equal parts and these partitions are called as Quartiles and these are the partitions values of Quantiles.
Deciles
The values which divide the given data into ten equal parts, say,  .
.
- : First decile which has 10% of the observations.
- : Second decile which has 20% of the observations.
- : Third decile which has 30% of the observations.
- : Tenth decile which has 100% of the observations.
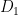 : First decile which has 10% of the observations.
: First decile which has 10% of the observations. : Second decile which has 20% of the observations.
: Second decile which has 20% of the observations. : Third decile which has 30% of the observations.
: Third decile which has 30% of the observations. : Tenth decile which has 100% of the observations.
: Tenth decile which has 100% of the observations.Percentiles
The percentiles are the values which divide the given data into hundred equal parts, say,  .
.
- : 1st percentile which has 1% of the observations.
- : 2nd percentile which has 2% of the observations.
- : 3rd percentile which has 3% of the observations.
- : 100th percentile which has 100% of the observations.
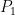 : 1st percentile which has 1% of the observations.
: 1st percentile which has 1% of the observations. : 2nd percentile which has 2% of the observations.
: 2nd percentile which has 2% of the observations. : 3rd percentile which has 3% of the observations.
: 3rd percentile which has 3% of the observations. : 100th percentile which has 100% of the observations.
: 100th percentile which has 100% of the observations.Tschebyschev’s Inequality
If we do not know the distribution of a random variable X, we can still make statements about the probability using Tschebyschev’s inequality that X takes values in a certain interval, (which has to be symmetric around the expectation  ) if the mean and the variance
) if the mean and the variance 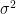 of X are known.
of X are known.
In simple words, we know that a random variable is always associated with some probability function such as:
- Probability mass function for a discrete random variable
- Probability density function for a continuous random variable
However, when we do not know any of these functions and still want to say the upper and lower limits of the values of a random variable. For those situation, Tschebyschev’s inequality helps us.
- If the variance is small, then a random variable is unlikely to be far from the mean.
Let X be a random variable with  and
and  . It holds that:
. It holds that:

or

After simplification, the value of X lies between  .
.
It means, the probability that the distance from the mean is larger than or equal to a certain number is, at most the variance divided by the square of that number.
Example 1:
Consider the continuous random variable waiting time for the train. Suppose that a train arrives every 20 minutes. Therefore, the waiting time of a particular person is random and can be any time contained in the interval [0,20].
Let X be a random variable.
The PDF is

Mean:

Variance:
![\begin{aligned} \sigma^2 &= Var(X) \\ &= \int_{-\infty}^{\infty} [x - E(X)]^2 f(x) dx \\ &=\int_{0}^{20} (x - 10)^2 \frac{1}{20} dx \\ &= \frac{100}{3}\end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Csigma%5E2+%26%3D+Var%28X%29+%5C%5C+%26%3D+%5Cint_%7B-%5Cinfty%7D%5E%7B%5Cinfty%7D+%5Bx+-+E%28X%29%5D%5E2+f%28x%29+dx+%5C%5C+%26%3D%5Cint_%7B0%7D%5E%7B20%7D+%28x+-+10%29%5E2+%5Cfrac%7B1%7D%7B20%7D+dx+%5C%5C+%26%3D+%5Cfrac%7B100%7D%7B3%7D%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
We can calculate the probability of waiting between 10 – 7 = 3 and 10+7 = 17 mins. Here, 3 is a lower and 17 is the upper limit values which can take a random variable X. If we compute probability value within the range:

Tschebyschev’s Inequality:
Suppose we don’t know the probability function (i.e., probability density function) but we know the mean ( ) and variance (
) and variance ( ).
).

 , It shows that the probability value should be at least 0.32.
, It shows that the probability value should be at least 0.32.
So comparing the results, with and without knowing the probability function is 0.7 and 0.32. It shows that knowing the probability density function gives a more precise result.
The exact probability is 0.7, which is relatively poor for approximate probability. One must remember that only the lack of distributional knowledge makes inequality worthwhile.
References
- Essentials of Data Science With R Software – 1: Probability and Statistical Inference, By Prof. Shalabh, Dept. of Mathematics and Statistics, IIT Kanpur.
CITE THIS AS:
“Probability and Statistical Inference – Quantiles and Tschebyschev’s Inequality” From NotePub.io – Publish & Share Note! https://notepub.io/notes/mathematics/statistics/statistical-inference-for-data-science/quantiles-and-tschebyschevs-inequality/
![]()
