In the previous note on Set Theory and Events, we have seen how the set theory can be used to model different kinds of events and derive a new event using the operations of set theory such as union, intersection, complement, and difference. This note will see the intuitive notion of probability, how relative frequency helps understand the intuitive notion of probability of the events and its limitation, then the actual axiomatic definition of probability.
The probability of an event is defined as the total number of favourable outcomes divided by the total number of possible outcomes. However, in this definition there is a problem in understanding it.
Intuitive notion of Probability
These is a close connection between the relative frequency and the probability of an event. This we will understand with an example in the below section.
Relative Frequency and Probability of an Event
Suppose an experiment has m possible outcomes or events such as  and the experiment is repeated n times. Now we will count how many times each of the possible outcome has occured.
and the experiment is repeated n times. Now we will count how many times each of the possible outcome has occured.
The absolute frequency  where
where  tells the number of times an event
tells the number of times an event  occurs.
occurs.
The relative frequency  of a random event
of a random event 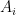 , with n repetitions of the experiment, is calculated as:
, with n repetitions of the experiment, is calculated as:  .
.
If we understand it from the descriptive statistics point of view, it is similar to the absolute and relative frequencies of the events from a random experiment.
If we assume that,
- The experiment is repeated a large number of times, then mathematically, it means that n tends to infinity.
- The experimental conditions remain the same (at least approximately) over all the repetitions.
the relative frequency 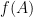 converges to a limiting value for A. The limiting value is interpreted as the probability of A and denoted by:
converges to a limiting value for A. The limiting value is interpreted as the probability of A and denoted by:

where  denotes the number of times an event A occurs out of n times.
denotes the number of times an event A occurs out of n times.
This is the probability what we always say. Whenever we say some event has a probability, it means if we try to repeat the experiment for a sufficiently large number of times and try to compute the relative frequency, then this relative value will converge to this particular value or probability of an event.
Suppose a fair coin, it means the probabilities of occurance of head and tail are equal, is tossed n = 10 times, the number of observed heads  times and number of observed tails
times and number of observed tails  times. Then, the relative frequencies in the experiment are:
times. Then, the relative frequencies in the experiment are:


When the coin is tossed a large number of times and n tends to infinity, then both  and
and  will have a limiting value 0.5 which is the probability of getting a head or tail in tossing a fair coin.
will have a limiting value 0.5 which is the probability of getting a head or tail in tossing a fair coin.
Example 1:
Suppose a fair coin is tossed five times, and the following outcomes are observed: {Head, Head, Tail, Head, Tail}, then relative frequencies of Tail = Probability of Tail = 2/5 and relative frequencies of Head = 3/5.
The same example, we will illustrate using the R programming language. In the R code, we have used the sample function, which generates sample data with argument size = 5,10,100, and so on with replacing the values.
# Experiment is repeated 5 times outcomes = sample(c(0,1), size=5,replace=T) print(outcomes) print(table(outcomes)/length(outcomes)) # Experiment is repeated 10 times outcomes = sample(c(0,1), size=10,replace=T) print(outcomes) # 1 1 1 0 1 0 1 1 1 1 print(table(outcomes)/length(outcomes)) # outcomes 0.2 0.8 # Experiment is repeated 100 times outcomes = sample(c(0,1), size=100,replace=T) outcomes print(table(outcomes)/length(outcomes))
After running the experiments 100 or more, we started getting relative frequencies of getting head or tail = 0.5 approximately.
Example 2:
Suppose we are tossing the six-sided fair die multiply times and observing the relative frequencies of getting each event. As we know that, the probability of occurrence of getting any number between 1 to 6 is 1/6 or 0.166.
# Experiment is repeated 5 times outcomes = sample(c(1,2,3,4,5,6), size=5,replace=T) print(outcomes) print(table(outcomes)/length(outcomes)) # Experiment is repeated 10 times outcomes = sample(c(1,2,3,4,5,6), size=10,replace=T) print(outcomes) print(table(outcomes)/length(outcomes)) # Experiment is repeated 100 times outcomes = sample(c(1,2,3,4,5,6), size=100,replace=T) outcomes print(table(outcomes)/length(outcomes)) # Experiment is repeated 1000 times outcomes = sample(c(1,2,3,4,5,6), size=1000,replace=T) print(table(outcomes)/length(outcomes))

Observations:
- When we ran the experiment 5 times, we got 2, 3, 5, 6 with relative frequencies, 0.2, 0.2, 0.2, 0.4, respectively. It means, 6 is repeated twice as compared to 2, 3, and 5 faces.
- When we ran the experiment 10 times, we got 1,2,3,5,6 with relative frequencies, 0.1, 0.1, 0.3, 0.3, 0.2, respectively. It means 3 and 5 repeated three times, six repeated two times, and four did not appear at all.
As we increase the number of experiments, values are moving toward 1/6 = 0.166, and this we can observe in the above diagram when we ran the experiment 1000 times.
Limitations
Although the above definition is certainly intuitively pleasing, but it possesses a serious drawback. How do we know that  will converge to some constant limiting value that will be the same for each possible sequence of repetitions of the experiment?
will converge to some constant limiting value that will be the same for each possible sequence of repetitions of the experiment?
For example, a coin is continously tossed repeatedly.
- How do we know that the proprotion of heads obtained in the first n tosses will converge to some value as n gets large?
- Even if it converges to some value, how do we know that, if the experiment is repeatedly performed a second time, we will again obtain the same limiting proportion of heads?
This issue is answered by starting the convergence of  to a constant limiting value as an assumption, or an axiom, of the system. However, to assume that will necessarily converge to some contant value is a complex assumption. Moreover, this limiting frequency exists, but it is difficult to belive a priori.
to a constant limiting value as an assumption, or an axiom, of the system. However, to assume that will necessarily converge to some contant value is a complex assumption. Moreover, this limiting frequency exists, but it is difficult to belive a priori.
In fact, it would be better to assume a set of simpler axioms about probability and then attempt to prove that such a constant limiting frequency does in some sense exist. And this approach is the modern axiomatic approach to probability theory. It works as follows:
- We assume that for each event A in the sample space
 there exists a value , referred to as the probability of A.
there exists a value , referred to as the probability of A. - We then assume that the probabilities satisfy a certain set of axioms which will be more agreeable with our intuitive notion of probability.
Axiomatic definition of Probability
From a purely mathematical viewpoint, suppose that for each event A of a random experiment having a sample space 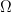 there is a number, denoted by
there is a number, denoted by 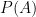 which satisfies the following three axioms:
which satisfies the following three axioms:
- Every random event A has a probability in the interval [0,1], i.e., . It states that the probability that the outcome of the experiment is contained in A is some number between 0 and 1.
- The sure event has probability 1, i.e., . It states that with probability 1, the outcome will be a member of the sample space .
- For any sequence of disjoint or mutually exclusive events, (that is, events for which when , , where n = . It states that for any set of mutual exclusive events the probability that at least one of these events occurs is equal to the sum of their respective probabilities. It is also called the theorem of additivity of disjoint events.
 . It states that the probability that the outcome of the experiment is contained in A is some number between 0 and 1.
. It states that the probability that the outcome of the experiment is contained in A is some number between 0 and 1. . It states that with probability 1, the outcome will be a member of the sample space
. It states that with probability 1, the outcome will be a member of the sample space  .
. (that is, events for which
(that is, events for which  when
when  ,
,  , where n =
, where n =  . It states that for any set of mutual exclusive events the probability that at least one of these events occurs is equal to the sum of their respective probabilities. It is also called the theorem of additivity of disjoint events.
. It states that for any set of mutual exclusive events the probability that at least one of these events occurs is equal to the sum of their respective probabilities. It is also called the theorem of additivity of disjoint events.Then, we call the probability of the event A.
Even the relative frequency of the event A when a large number of repetitions of the experiment are performed, then would indeed satisfy the above axioms.
Rules of Probability
These rules are helpful for modeling and calculating the probabilities of the events.
- The probability of occurrence of an impossible event is zero:
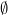 is zero:
is zero:
Example 1:
Suppose a box of 30 ice creams contains ice creams of 6 different flavours with 5 ice creams of each flavour. Suppose an event A is defined as A = {“Vanilla flavour”}, then the probability of finding a vanilla flavour ice cream is:
P(A) = 5/30
The probability of the complementary event  , i.e., the probability of not finding a vanilla flavour ice cream is:
, i.e., the probability of not finding a vanilla flavour ice cream is:
P(“No Vanilla falvour”) = 1 – P(“Vanilla flavour”) = 1- 5/30 = 25/30.
- The probability of occurrence of a sure event is one:
 = 1
= 1
- The probability of the complementary event of A, (i.e. ) is:

- The odds of an event A is defined by:

Thus the odds of an event A tells how much more likely it is that A occurs than that it does not occur.
- Additive theorem of Probability:
Let 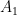 and
and  be not necessarily disjoint events. The probability of occurrence of and is:
be not necessarily disjoint events. The probability of occurrence of and is:

The meaning of “or” is in the statistical sense: either is occurring, is occurring, or both of them. In this case, as and are the disjoint event, the  .
.
Example 1:
Suppose a total of 28% people like sweet snacks, 7% like salty snacks, and 5% like both sweet and salty snacks. The percentage of people like neither sweet nor salty snacks is obtained as follows:
Let be the event that a randomly chosen person likes sweet snacks and be the event that a randomly chosen person likes salty snacks. As we can see that events and not a disjoint events.
The probability that a person likes either sweet or saulty snacks is  :
:
 = 0.07 + 0.28 – 0.05 = 0.30
= 0.07 + 0.28 – 0.05 = 0.30
Thus, 70% of people does not like either sweet or salty snacks.
- Sample spaces having equally likely outcomes:
For a large number of experiments, it is natural to assume that each point in the sample space is equally likely to occur. For many experiments whose sample space is a finite set, say ![\Omega = {1,2,3], \cdots , N}](https://s0.wp.com/latex.php?latex=%5COmega+%3D+%7B1%2C2%2C3%5D%2C+%5Ccdots+%2C+N%7D&bg=ffffff&fg=000&s=0&c=20201002) , it is often natural to assume that:
, it is often natural to assume that:
P({1}) = P({2}) = …. = P({N}) = p (say)
Sum of total probabilities = = P({1}) + P({2}) + …. + P({N})= Np, so the probability of each event is 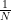 .
.
If we assume that each outcome of an experiment is equally likely to occur, then the probability of any event A = the proportion of points in the sample space that are contained in A.
Thus, to compute probabilities, it is necessary to konw the number of different ways to count given events. For that we need to have the knowledge of principle of counting. This is our next topic of discussion.
Q&A
From this note, we can get answers to the following questions.
- How Probability and Relative Frequency of events are related to each other?
- What is the axiomatic definition of Probability?
- What is the theorem of additivity of disjoint events in Probability?
- What is equally likely evenst in Probability?
References
- Essentials of Data Science With R Software – 1: Probability and Statistical Inference, By Prof. Shalabh, Dept. of Mathematics and Statistics, IIT Kanpur.
![]()
