In the previous note on the Probability and Statistical Inference, we started a new topic that characterizes the probability distribution of a random variable to get the hidden statistical information about the probability distribution. One of the statistical tools is the expectation of random variables or expectation of the probability distribution of a random variable. We have seen what an expectation is and how to compute the expectation of discrete and continuous random variables.
In this note, we will further explore various tools and techniques that help us characterize the probability distribution of a random variable to get latent information about the random process.
Introduction
Whenever data comes from some process or experiment, we assume that process can be modeled through probability mass function or probability density function depending on whether the random variable is continuous or discrete. In contrast, suppose there is a curve or graph representing the probability function. By knowing the curve, we can learn more about the probability function of the curve. For example, whether it is symmetric, non-symmetric, humpy, etc.
These statistical tools provide us with the hidden information contained inside the data. The different types of information exist, and these qualities will help us a lot in data science whenever we try to get the actual data without looking into the real data (population data).
The concept of moments is also a particular type of expectation. Moments give enormous information in a quantitative form, which we can’t get or see using graphical or plotting tools when a random variable contains lots of values or large data sets.
Moments
Moments are used to describe different characteristics and features of a probability distribution. These characteristics are: central tendency, disperson, symmetry and peakedness of probability curve. For example:

So these kinds of information will be computed by Moments which is essential from the analysis and quantitative point of view in Data Science. To understand the Moments, we will first revisit the expectation of random variables concepts, which we studied in the earlier notes of Essential of Data Science.
Expectation of Random Variables
Let X be a continuous random variable with probability density function f(x). Suppose g(X) is a real valued function of X. The expectation of g(X) is defined as:
![E[g(X)] = \int_{-\infty}^{\infty} g(x) f(x) dx](https://s0.wp.com/latex.php?latex=E%5Bg%28X%29%5D+%3D+%5Cint_%7B-%5Cinfty%7D%5E%7B%5Cinfty%7D+g%28x%29+f%28x%29+dx&bg=ffffff&fg=000&s=0&c=20201002)
Provided that  .
.
Let X be a discrete random variable having the probability mass function 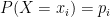 . Suppose g(X) is a real valued function of X. Thus, X takes the values
. Suppose g(X) is a real valued function of X. Thus, X takes the values 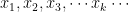 with respective probabilities
with respective probabilities  and if the expectation of g(X) exists then,
and if the expectation of g(X) exists then,
![\begin{aligned}E[g(X)] &= \sum_{i=1}^{\infty} g(x_i)P(X=x_i) \\ &= \sum_{i=1}^{\infty} g(x_i)p_i \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7DE%5Bg%28X%29%5D%C2%A0+%26%3D+%5Csum_%7Bi%3D1%7D%5E%7B%5Cinfty%7D+g%28x_i%29P%28X%3Dx_i%29+%5C%5C+%26%3D+%5Csum_%7Bi%3D1%7D%5E%7B%5Cinfty%7D+g%28x_i%29p_i+%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
Provided that 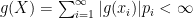 .
.
Moment about the origin (Raw Moment)
Let 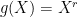 where r is nonnegative integer, then
where r is nonnegative integer, then
![E[g(X)] = E(X^r) = \mu^\prime_r](https://s0.wp.com/latex.php?latex=E%5Bg%28X%29%5D+%3D+E%28X%5Er%29+%3D+%5Cmu%5E%5Cprime_r&bg=ffffff&fg=000&s=0&c=20201002)
where  is called as
is called as  moment of X about origin or point a zero.
moment of X about origin or point a zero.
Moment about an Arbitrary Point A
Let  where r is nonnegative integer, then
where r is nonnegative integer, then ![E[g(X)] = E(X - A)^r](https://s0.wp.com/latex.php?latex=E%5Bg%28X%29%5D+%3D+E%28X+-+A%29%5Er+&bg=ffffff&fg=000&s=0&c=20201002) is called as moment of X about the point A.
is called as moment of X about the point A.
Central moments
When A =  , then
, then ![E[(X-A)^r] = E[X - E(X)]^r = \mu^r](https://s0.wp.com/latex.php?latex=E%5B%28X-A%29%5Er%5D+%3D+E%5BX+-+E%28X%29%5D%5Er+%3D+%5Cmu%5Er&bg=ffffff&fg=000&s=0&c=20201002) , where,
, where, 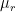 is called as central moment of X. It is called central moment because moment is measured around the mean.
is called as central moment of X. It is called central moment because moment is measured around the mean.
The moments of variable X about the arithmetic mean ( or sample mean) 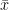 are called central moments. In general, the
are called central moments. In general, the  sample central moment based on observations
sample central moment based on observations 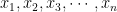 is defined as follows:
is defined as follows:
= 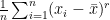
Observations:
- When r = 0,

- When r = 1, . It is zero because is a constant (mean value) and only.
- When r = 2, . It is called sample variance.
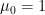
 . It is zero because
. It is zero because  is a constant (mean value) and
is a constant (mean value) and  only.
only.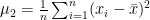 . It is called sample variance.
. It is called sample variance.Variance of Random Variables
In general, when A = and r = 2, then:
![E[(X-A)^2] = E[X - E(X)]^2 = \mu^2 = \sigma^2](https://s0.wp.com/latex.php?latex=E%5B%28X-A%29%5E2%5D+%3D+E%5BX+-+E%28X%29%5D%5E2+%3D+%5Cmu%5E2+%3D+%5Csigma%5E2&bg=ffffff&fg=000&s=0&c=20201002) is called the variance of X.
is called the variance of X.
It computes the variation of X relative to mean value.
The variance of a continuous random variable X is define as:
![\begin{aligned} Var(X) &= E[X - \mu]^2 \\ & = \int_{-\infty}^{\infty} [x - \mu]^2 f(x)dx \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+Var%28X%29+%26%3D+E%5BX+-+%5Cmu%5D%5E2+%5C%5C+%26+%3D+%5Cint_%7B-%5Cinfty%7D%5E%7B%5Cinfty%7D+%5Bx+-+%5Cmu%5D%5E2+f%28x%29dx+%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
Where 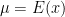 .
.
For a discrete random variable X, the variance of X is defined as:
![\begin{aligned} Var(X) &= E[X - \mu]^2 \\ &= \sum_{i=1}^{n} [x_i - \mu]^2 P(X= x_i) \\ &= \sum_{i=1}^{n} [x_i - \mu]^2 p_i \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+Var%28X%29+%26%3D+E%5BX+-+%5Cmu%5D%5E2+%5C%5C+%26%3D+%5Csum_%7Bi%3D1%7D%5E%7Bn%7D+%5Bx_i+-+%5Cmu%5D%5E2+P%28X%3D+x_i%29+%5C%5C+%26%3D+%5Csum_%7Bi%3D1%7D%5E%7Bn%7D+%5Bx_i+-+%5Cmu%5D%5E2+p_i+%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
Expectation and Variance of a Random Variable
These are different measures to summarize a probability distribution for a random variable X.
- Mean is a measure of the central tendency of the probability distribution.
- Variance measures the dispersion or variability in the probability distribution.
It may be possible that two different distributions have the same mean and variance. But, knowing the mean and variance, we can’t predict the probability distribution as these measures do not uniquely identify a probability distribution.
Example 1:
Consider the continuous random variable “waiting time for the train.” Suppose that a train arrives every 20 minutes. Therefore, the waiting time of a particular person is arbitrary and can be any time contained in the interval [0, 20]. The required probability density function is:
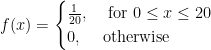
Let X be a continuous random variable for a waiting time for the train. The expected waiting time is as follows:

The variance of a continuous random variable is as follows:
![\begin{aligned} Var(X) &= \int_{-\infty}^{\infty} [x - E(X)^2] f(x) dx \\ &= \int_{0}^{20} (x - 10)^2 \frac{1}{20} dx \\ &= \frac{100}{3} \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+Var%28X%29+%26%3D+%5Cint_%7B-%5Cinfty%7D%5E%7B%5Cinfty%7D+%5Bx+-+E%28X%29%5E2%5D+f%28x%29+dx+%5C%5C+%26%3D+%5Cint_%7B0%7D%5E%7B20%7D+%28x+-+10%29%5E2+%5Cfrac%7B1%7D%7B20%7D+dx+%5C%5C+%26%3D+%5Cfrac%7B100%7D%7B3%7D+%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
Example 2:
Suppose we roll a dice and rewards are considered in the following ways:

In this example, Point(x) represents a number that appears on the upper face of the die, and Reward (INR) represents rewards for different values of x. However, each outcome’s probabilities are equally likely, which means anyone occurs with the same probability.
The expected reward means when we play this game a significantly higher number of times, the accumulated rewards would be equal to the expected reward value.
- Expected reward, = Rs. 1 * 1/6 + Rs. 2 * 1/6 + Rs. 3 * 1/6 + Rs. 4 * 1/6 + Rs. 5 * 1/6 + Rs. 6 * 1/6 = Rs. 3.50

![Var(X) = E(X^2) - [E(X)]^2 = 91 - 3.5 \times 3.5 = 78.75](https://s0.wp.com/latex.php?latex=Var%28X%29+%3D+E%28X%5E2%29+-+%5BE%28X%29%5D%5E2+%3D+91+-+3.5+%5Ctimes+3.5+%3D+78.75+&bg=ffffff&fg=000&s=0&c=20201002)
Standard Deviation
Standard deviation (or standard error) has an advantage that it has the same units as of data, so easy to compare.
For example, if x is in meter, then 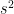 is in
is in  which is not so convenient to interpret. On the other hand, if x is in metr, then s is in meter wihch is more covenient to interpret.
which is not so convenient to interpret. On the other hand, if x is in metr, then s is in meter wihch is more covenient to interpret.
Notations to represent standard deviation for sample and population.
- Sample Variance is represented as .
- Positive square root of is called as standard error.
- Population Variance is represented as .
- Population standard deviation is represented as
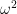 .
.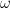
Variance (or standard deviation) measures how much the observations vary or how the data is concentrated around the arithmetic mean. Standard deviation has its own interpretation and which is represented as follows:
- Lower value of variance ( or standard deviation, standard error) indicates that the data is highly concentrated or less scattered around the mean.The lower value of variance is preferable.
- Higher value of variance ( or standard deviation, standard error) indicates that the data is less concentrated or highly scattered around the mean.
References
- Essentials of Data Science With R Software – 1: Probability and Statistical Inference, By Prof. Shalabh, Dept. of Mathematics and Statistics, IIT Kanpur.
CITE THIS AS:
“Moments and Variance” From NotePub.io – Publish & Share Note! https://notepub.io/notes/mathematics/statistics/statistical-inference-for-data-science/moments-and-variance/
![]()
