In the previous note on continuous random variables, we have seen what a continuous random variable is and its distribution function. The distribution function is expressed in terms of probability density function (PDF) that helps us to compute the statistical parameters of continuous random variable.
In this note, we will further extend the concept of the random variable and explore discrete random variable and its distribution function. In this case, it is expressed in terms of probability mass function (PMF).
Introduction
Whenever a sample space contains the integer numbers or subset of integer numbers, we express experiment data or sample space using a discrete random variable to model it mathematically.
Further, to extract meaningful information from the discrete random variable, we use the distribution function, and in this case, the distribution function is represented as a probability mass function. However, the cumulative distribution function uses the probability mass function and cumulatively computes the probability values. And outcomes of the distribution function are helpful to understand the random variable properties statistically.
Note: The random variable is a generic term, and it can be a discrete or continuous random variable. In the same way, the distribution function is a generic term, and the probability mass function and probability density function are the distribution functions for discrete and continuous random variables, respectively.
Discrete Random Variable
A random variable X is defined to be discrete if its probability space is either finite or countable, i.e., it takes only a finite or countable number of values. A set V is called a countable if its elements can be listed. It means there is a one-to-one correspondence between the set V and the positive integers.
Let us understand discrete random variables using an example explained in the below paragraph.
Suppose X denotes the random variable as the number of defective components in an electronic device. The device possesses several characteristics, and the random variable X summarises the device only in terms of the number of defects. Further, the possible values of X are integers from zero up to some large value that represents the maximum number of defects that can be found on one of the devices. Furthermore, if this maximum number is enormous, we might assume that the X range is the set of integers from zero to infinity.
Probability Distribution
The probability distribution of a random variable X is a description of the probabilities associated with the possible values of X. For a discrete random variable, the distribution is specified by a list of the possible values along with the probability of each. It is a convenient way to express the probability in terms of a formula.
For example,
- If an experiment follows a uniform distribution, we have a predefined probability mass function (PDF) and cumulative distribution function (CDF). And knowing PDF and CDF, we can quickly compute other statistical parameters that are helpful to understand the outcomes of an experiment statistically.
In practice, a random experiment can offen be summarized with a random variable and its distribution. However, the details of the sample space can often be omitted.
Example 1: Tossing a coin
Consider tossing a coin where each trial results in either a head (H) or a tail (T), and each occurs with the same probability, which is 1/2.
The sample space is 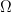 = {H,T}.
= {H,T}.
Let X: number of head.
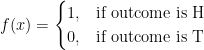
Example 2: Tossing two coins
When two coins are tossed, we can observe the outcomes as: = {HH, HT, TH, TT}. Assuming that each outcome is equally likely then the each occurs with the same probability, which is 1/4.
Let X: Number of heads.
 .
.
It is just a mapping of outcomes to integer values.
Clearly, the sample space of X is the set (0,1,2). We can see that X is a discrete random variable because its space is finite and can be counted.
Suppose we want to find the probability distributation of a random variable X. Using independene and equally likely assumptions for events are as follows:
- P(X = 0) = 1/4
- P(X=1) = 1/4 + 1/4 = 1/2
- P(X=2) = 1/4.
The following depicts the distribution of probability over the elements of range of X.
| x | 0 | 1 | 2 |
| P(X=x) | 1/4 | 1/2 | 1/4 |
The cumulative distribution are as follows:



Probability Mass Function (PMF)
The probability distribution of a random variable X is a description of the probabilities associated with the possible values of X. For a discrete random variable, the distribution is specified by a list of the possible values along with the probability of each. However, in some cases, it is convenient to express the probability in terms of a formula.
Let X be a discrete random variable which takes k different values. The probability mass function (PMF) of X is given as follows:

Where  is a probability mass function,
is a probability mass function, ![P(X=x_i]](https://s0.wp.com/latex.php?latex=P%28X%3Dx_i%5D&bg=ffffff&fg=000&s=0&c=20201002) represents a probability value when a random variable X takes a value called
represents a probability value when a random variable X takes a value called  .
.
It is required that the probabilities 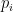 satisfy the following conditions:
satisfy the following conditions:
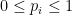

Cumulative Distribution Function (CDF)
The cumulative distribution function CDF of a discrete random variable as,
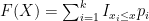
Where I is an indicator function defined as follows:
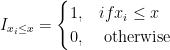
The CDF of a discrete variable is always a step function. And knowing the CDF, we can calculate various types of probabilities for discrete random varaibles using it.
Let a. and b be some known constants, then




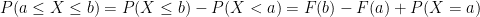


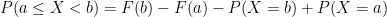
Example 1: Rolling of fair six sided die
There are six possible outcomes of rolling a die. Let X be a discrete random variable which is defined as follows: X = Number of dots observed on the upper surface of the die. The six possible outcomes can be as follows.
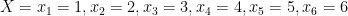
The PMF is defined as follows:

If we plot the values of  , then we will get the following graph. For each value of we will get the probability value of 1/6, which is not true in the case of CDF.
, then we will get the following graph. For each value of we will get the probability value of 1/6, which is not true in the case of CDF.

The CDF is defined as follows:

CDF gives the cumulative values, suppose we want to find  :
:


Example 2: Sum of two numbers from two different sets.
Suppose m and n are two numbers such that m = 1,2,3 and n = 1,2. Let X be a discrete random variable which is defined as follows: X = All pairs of sum of number from two sets, such as X(m,n) = m + n.
Clearly, there are four possible outcomes that are as follows: (2, 3, 4, 5) from the sample space {(1,1),(1,2),(2,1),(2,2),(3,1),(3,2)}. For example. X(m,n) = X(1,1) = 2, X(1,2) = 3, and so on.
The PMF is defined as follows:
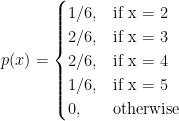
The CDF is defined as follows:
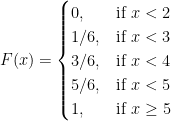
Observe that F is a step function increasing only by jumps. If F is a step function, then the correspoinding random variable is discrete.

References
- Essentials of Data Science With R Software – 1: Probability and Statistical Inference, By Prof. Shalabh, Dept. of Mathematics and Statistics, IIT Kanpur.
CITE THIS AS:
“Discrete Random Variables” From NotePub.io – Publish & Share Note! https://notepub.io/notes/mathematics/statistics/statistical-inference-for-data-science/discrete-random-variables/
![]()
