To understand the need for Nonparametric statistical analysis methods, we should first know what a parametric statistical inference is, or we often called statistical inference.
Parametric Statistical Inference
Statistical inference is the process of analyzing sample data to deduce properties of an underlying distribution of population. Typically it is assumed that the data set of the population is enormous, and we cannot study the entire population. Otherwise, if we can, there is no need for statistical inferences; we can calculate all the parameters and make the decisions.
To understand it, let us take an example, suppose we have a massive dataset that we can not collect. Therefore, we sample some data from the large population, for which we want to infer. In that case, we take a small sample typically randomly chosen, and based on that, we infer about the population parameters, or sometimes we compare two populations parameters.
Suppose our task is to find the average male height in India. It is nearly impossible to go and measure each individual. So the alternative solution is to collect a set of random samples and infer the actual population parameters. In this case, it is the average height of an Indian male.
The basic tasks of statistical inference may be categorized as:
- Estimation of a distribution parameter such as central tendency, which includes Mean, Median, Mode, etc., and data variability, including mean absolute deviation, squared deviation – variance, and standard deviation.
- Comparison of two population parameters, namely Mean and Variance. For example, suppose we have two groups of students, and we want to compare whether they have the same mean and variance or, if not, then, what is the relationship between them.
- Testing of Hypothesis: whether sample gives enough evidence in support of some assumed value
 for some distribution parameter . For example, wherever we talk about certain distribution, we associate with them certain parameters, and these are as follows:
for some distribution parameter . For example, wherever we talk about certain distribution, we associate with them certain parameters, and these are as follows:
- For Normal Distribution: It is represented as also called probability density function and it has two important parameters, , and . The important measures are computed using these parameters, fortunatuly, , and represent arthematic mean and variance respectively.
- For Binomial Distribution: It is represented as , and it also has two parameters, n = number of trials and p = probability of success. Using these parameters, mean is calculated as np, and variance is calculated as np(1-p).
- For Normal Distribution: It is represented as
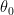 for some distribution parameter
for some distribution parameter  . For example, wherever we talk about certain distribution, we associate with them certain parameters, and these are as follows:
. For example, wherever we talk about certain distribution, we associate with them certain parameters, and these are as follows: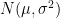 also called probability density function and it has two important parameters,
also called probability density function and it has two important parameters,  , and
, and 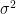 . The important measures are computed using these parameters, fortunatuly,
. The important measures are computed using these parameters, fortunatuly,  , and it also has two parameters, n = number of trials and p = probability of success. Using these parameters, mean is calculated as np, and variance is calculated as np(1-p).
, and it also has two parameters, n = number of trials and p = probability of success. Using these parameters, mean is calculated as np, and variance is calculated as np(1-p).Thus, it implies that if we can estimate the distribution parameters, we can get a feel of the overall population.
Parametric Statistical Inference underlying Assumptions
These are the robust statistical methods such as Z-test, T-test, chi-square test, F-test, etc. However, these are worked based on certain assumptions. In particular, most parametric methods assume that:
- Data is Quantitative: It means when it is not quantitative, the statistical methods will not work. Even in practice, data are nominal and ordinal as well.
- For example, the ranks of first, second, and third position holders are 90, 80, and 60 compared to 90, 85, and 80 in the second case. In the second case, a student who scored 80 is in the third position, whereas in the first case, a student who scored 80 is in the second position. This way, with the ordinal data type, we lose much information, and the comparison of variables is difficult.
- The population has a normal distribution (Normality Property): It will be more or less symmetrically spread around the mean. However, it may also be possible that the population is too small to be treated as normal.
- First solution: If the normal distribution is not appropriate, it is common to consider a transformation of the data. Normal-theory methods may be applied to the transformed data. The standard transformation is log, square root, etc.
- Second solution: It is often advised to try with other known but non-normal distributions, such as exponential, etc.
- Third solution: Switch to Nonparametric mode.
- The sample size is sufficiently large: It means, to infer for the population, we need quite a large sample size. But in practice, it always does not happen.
References
![]()