We have covered the measures of data variability based on the absolute deviation in the earlier note, where we measure the variation from any arbitrary value. We have also covered mean absolute deviation. Instead of measuring from an arbitrary value, it uses mean, median, or mode as a fixed value and measures the deviation.
We have also seen that deviation can be positive, negative, or zero. But if we consider negative deviation, then it may be possible that negative and positive values may cancel out during summing, and the resultant outcome may not be correct. For that reason, we only take magnitude rather than direction or signs.
Measures of Deviations
There are two aspects to measure the magnitude of the deviations. The first aspect is by measuring the absolute value of all the deviations and the second aspect is by taking the squared values of all the deviations. This note will cover the methods that take squared values of all the deviations to measure data variability.
Absolute deviation vs Squared deviation
Absolute and squared deviations both measure the dispersion. However, absolute deviation uses L1 norm or Manhattan distance, whereas squared deviation uses euclidian distance. The dispersion ratio is more significant in the case of squared deviation, as it calculates the square differences.
Mean Squared Error
In the note on variability based on deviation, we have seen absolute deviation, where we calculate the deviation of observations from any fixed point. In the same way, if we compute squared deviations of all observations from a fixed point then it is called mean squared error. The mean squared error does not resemble that we are computing squared deviation from the mean of entire observations.
There are discrete (ungrouped) and continuous (grouped) variable types of datasets. In discrete variables, we try to use the observations as such. But, in the case of a continuous variable, we try to group them based on the class intervals, convert the data into a frequency table, and extract mid-values of the class intervals and the corresponding frequency to construct the statistical measures.
Mean Squared Error for discrete data
Suppose we have n observations,  on a discrete variable X. To calculate the mean squared error around any point A. In general, it looks like as follows:
on a discrete variable X. To calculate the mean squared error around any point A. In general, it looks like as follows:
 , for all n observations
, for all n observations
While doing that, we squared all the deviation values. For example, squared deviation of a value 5 from a fixed value, 10 is equal to  = 25. In the end, we will sum of all squared deviation values and divided by number of observations. It is represented as follows:
= 25. In the end, we will sum of all squared deviation values and divided by number of observations. It is represented as follows:
Mean Squared Error (MSE),  =
= 
Mean Squared Error for continuous data
Suppose we have observations on a variable X and having k class intervals such as  in a frequency table. The midpoint value is obtained for each interval is as follows:
in a frequency table. The midpoint value is obtained for each interval is as follows:
 , where i < j
, where i < j
and associated absolute frequency is  for the class interval
for the class interval  . The represents a number of observations belong to the class interval . The sum of all the absolute frequencies must be n =
. The represents a number of observations belong to the class interval . The sum of all the absolute frequencies must be n =  .
.
Mean Squared Error (MSE), = 
Here, , represents Mean Squared Error of samples around A.
Variance
The mean squared error (MSE) with respect to A is minimum when A is not any arbitrary fixed value rather than it is an arithmetic mean  of the entire observations. In other words, mean squared error takes the minimum value, when the deviations are measured around the arithmetic mean. It is also called Variance.
of the entire observations. In other words, mean squared error takes the minimum value, when the deviations are measured around the arithmetic mean. It is also called Variance.
Information about notations: when we compute variance for samples and population, it is represented as  and
and 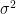 respectively.
respectively.
Variance for discrete or ungrouped data
We use the same concept for the discrete data or ungrouped data as explained in the mean squared error for discrete data section. We will replace A as an arbitrary value to mean value, and rest remains the same.
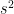 =
=  , where
, where  .
.
Variance for continuous or grouped data
We use the same concept for the continuous data or grouped data as explained in the mean squared error for continuous data section. We will replace A as an arbitrary value to mean value, and the rest remains the same. The final formula looks as follows:
= 
In statistics, another formula for variance is also very popular, and in this case, instead of dividing by n (it represents n observations), we take n-1.
Biased and Unbiased Estimator
Before going to understand biased and unbiased estimators, let us first understand what an estimator is. It is a sample statistic that estimates population parameters. In simple words, we mainly estimate the population from sample data. It is essential as we can not collect entire population data, so the only alternative is to approximate population parameters from statistics of sample data. There are different types of estimators, such as biased and unbiased estimators.
In statistical inference, when we use n-1 instead of n, this form of the variance is an unbiased estimator of the population variance. The formula looks as follows for discrete variable:
=  , where .
, where .
and for continuous variable or grouped data, it looks as follows:
= 
Whereas, when we divide by n, it is a biased estimator of the population variance. Now the question comes in our mind, when it is essential to taken care, and which estimate need to be used. In the case of small data, the values of the variances computed by using the n-1 and n make impacts. However, in the case of a large dataset, the values of the variances may not differ much using biased or unbiased estimator.
Standard Deviation
Variance is measured based on the average squared deviation from the mean to all the data points. However, the calculated variance value is not on the scale as compared to the input data value. So to get the dispersion on the same scale as input data, we take the square root of the variance, called standard deviation.
For example, suppose we have sample data of the height of students in centimeters from a classroom. The calculated mean heigh will be in centimeter too, but the variance will be in centimeter square. Thus, it is not convenient to interpret any meaningful comparison while seeing the variance and sample data compared to standard deviation and sample data as these are in the same scale, i.e., centimeter.
It has an advantage that is has the same units or scales as of data, so easy to compare.
When the variance is computed from the sample data then it is called sample variance and it is represented as and similarly sample standard deviation is represented as  . Whereas, in the case of population variance it is represented as and
. Whereas, in the case of population variance it is represented as and  for population standard deviation. Kindly note, irrespective of sample variance or population variance, we always call it without loss of generality as variance and similarly for standard deviation.
for population standard deviation. Kindly note, irrespective of sample variance or population variance, we always call it without loss of generality as variance and similarly for standard deviation.
Importance of Variance or Standard Deviation
Variance or standard deviation measures how much the observations vary or how the data is concentrated around the arithemetic mean.

In the above diagram, there are two variables, and it is represented with red and blue colors. From the 1st variable (blue), we can interpret that entire data points are concentred towards the center. Thus, it has low variance than the 2nd variable (red), where data is well spread and has higher variance.
- Lower value of variance indicates that the data is highly concentrated or less scattered around the mean.
- Higher value of variance indicates that the data is less concentrated or highly scattered around the mean.
References
- Descriptive Statistic, By Prof. Shalabh, Dept. of Mathematics and Statistics, IIT Kanpur.
![]()