In this note series, we had already covered a few of the different tools and techniques to measure the central tendency of data. Moreover, in the current note, we will understand the Mode and how it measures the central tendency of data.
Mode in Descriptive Statistics
Mode tells which observation has occurred or recorded a maximum number of times. It is defined as, having a  observations
observations  which occurs the most, compared with all other observations. The significance of mode can be easily understood by seeing the below examples:
which occurs the most, compared with all other observations. The significance of mode can be easily understood by seeing the below examples:
- A restaurant owner wants to know which of the dish is more preferred.
- A clothing shop owner wants to know which size of the shirt and or trouser is largest in demand.
Mode is the value that occurs most frequently in a set of observations, and it is preferable to gather these kinds of information. However, we will see why Mean and Median fails compared to Mode.
- Mean fails as it is highly vulnerable when there are outliers in the observation set.
- Median fails, as it divides entire observations into two different partitions and does not give the observation values which occurred the maximum number of times.
Type of Mode Distributions
Mode usually follows these kinds of distributions as mentioned below:
- When the observation data or a variable shows only a single peak, it is called unimodal distribution.
- When the observation data or a variable produces two peaks, then that distribution is called bimodal distribution.
- When the observation data or a variable has multiple peaks, that distribution is called multimodal distribution.
Example of bimodal distribution
To draw a bimodal distribution, we have taken observations from two different normal distributions with separate mean and variance and merge their observation values into a variable and plot the histogram.
# Example to draw bimodal distribution import numpy as np from numpy.random import normal from matplotlib import pyplot as plt # Generate observation from normal distribution # where loc is mean and scale is spread var_1 = normal(loc=200, scale=10, size=3000) var_2 = normal(loc=400, scale=10, size=9000) # Merge the observation data into a single variable var = np.hstack((var_1, var_2)) # Plot the histogram # To set the figure size and clarity plt.figure(figsize=(10,3),dpi=200) plt.hist(var, bins=50) plt.show()
The above code generates a histogram, and it is shown as follows:

Even we can draw using the Kernel Density Estimates (KDE) to see the smoothness in the curse. It is achieved using the below code snippet. In this case, we have changed the mean value and kept the same variance for two different normal distributions.
# Example to draw bimodal distribution import numpy as np from numpy.random import normal from matplotlib import pyplot as plt import seaborn as sns # Generate observation from normal distribution # where loc is mean and scale is spread var_1 = normal(loc=10, scale=100, size=3000) var_2 = normal(loc=600, scale=100, size=9000) # Merge the observation data into a single variable var = np.hstack((var_1, var_2)) # To set the figure size and clarity plt.figure(figsize=(10,3),dpi=200) sns.distplot(var,kde=True) plt.show()

Mode for ungrouped Data
For discrete variables, the mode of a variable is the value of the variable having the highest frequency in a unimodal distribution.
Example code to calculate Mode in Python
We used Python numpy.random.randint function to generate discrete random numbers in a range of 1-10 of 200 observations and used scipy.stats.mode function to compute mode. The procedure is written in the Python code snippet.
import math import numpy as np import matplotlib.pyplot as plt from scipy import stats # Variable contains discrete values. var = np.random.randint(1,high=10,size=200) print(var) # Find mode using stats.mode() mode = stats.mode(var) print(mode)
As an output, it displays 200 observations as an input and the Mode value of the observations. The above code produces different results in a different run as observations are randomly generated in each run.

Mode for grouped Data
For a continuous variable, the mode is the value of the variable with the highest frequency density corresponding to the ideal distribution, which would be obtained if the total frequency were increased indefinitely and if, at the same time, the width of the class intervals were decreased indefinitely.
In the earlier notes, we have seen that we need to create a frequency table whenever we are working on continuous variables, which includes class interval, midpoint, and absolute frequency values of each class interval.
We will use the tips dataset to draw a frequency table of a continuous variable called total bill and plot the table using the Python code snippet.
Example code to compute frequency distribution in Python for Mode
import seaborn as sns
import pandas as pd
import numpy as df
import math
import matplotlib.pyplot as plt
# Load tips dataset from seaborn package
tips_data = sns.load_dataset('tips')
max_bill_amount = int(math.ceil(tips_data['total_bill'].max()))
interval_len = int(math.ceil(max_bill_amount/10))
sum_of_total_bills = tips_data['total_bill'].sum()
# Create a class interval automatically
total_bins = [i for i in range(0,max_bill_amount+interval_len,interval_len)]
total_bills_groupby_interval = pd.cut(x=tips_data['total_bill'], bins=total_bins)
# Calculate absolute frequency
absolute_frequency_table = tips_data.groupby(total_bills_groupby_interval)['total_bill'].count()
# Renaming headers and put into dataframe
frequency_table = pd.DataFrame({'Class Interval':absolute_frequency_table.index, 'Absolute Frequency':absolute_frequency_table.values})
# Find midpoint value of each interval
left = frequency_table['Class Interval'].apply(lambda x: x.left).astype(float)
right = frequency_table['Class Interval'].apply(lambda x: x.right).astype(float)
frequency_table['Mid Point'] = (left+right)/2
frequency_table
The above code produces the following output as a frequency table.

Formula to calculate Mode for grouped data
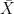 =
= ![e_{l} + \left [ \frac{f_0 + f_{-1}}{(f_0 - f_1) + (f_0 - f_{-1})} \right ] \times d_l](https://s0.wp.com/latex.php?latex=e_%7Bl%7D+%2B+%5Cleft+%5B+%5Cfrac%7Bf_0%C2%A0+%2B%C2%A0+f_%7B-1%7D%7D%7B%28f_0%C2%A0+-%C2%A0+f_1%29+%2B+%28f_0%C2%A0+-%C2%A0+f_%7B-1%7D%29%7D+%5Cright+%5D+%5Ctimes+d_l+&bg=ffffff&fg=000&s=0&c=20201002)
 : Lower limit of modal class
: Lower limit of modal class- : Class width
- : Frequency of model calss, where modal class is corresponding to the maximum frequency
- : Frequency of the class just before the modal class
- : Frequency of the class just after the modal class
 : Lower limit of modal class
: Lower limit of modal class : Class width
: Class width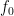 : Frequency of model calss, where modal class is corresponding to the maximum frequency
: Frequency of model calss, where modal class is corresponding to the maximum frequency : Frequency of the class just before the modal class
: Frequency of the class just before the modal class : Frequency of the class just after the modal class
: Frequency of the class just after the modal class# Step1: Find the modal class #. which has maximum frequency modal_class = frequency_table["Absolute Frequency"].idxmax() left_val = frequency_table['Class Interval'].apply(lambda x: x.left).astype(float) e_l = left_val[modal_class] d_l = interval_len f_0 = frequency_table["Absolute Frequency"][modal_class] f_neg_1 = frequency_table["Absolute Frequency"][modal_class-1] f_1 = frequency_table["Absolute Frequency"][modal_class+1] x = e_l + ((f_0 + f_neg_1)/((f_0 - f_1) + (f_0 - f_neg_1))) * d_l print(x)
We implemented the above formula shown in the above code snippet to calculate the mode for grouped data. As a result, we received a mode value of 21.03. In the previous notes, we have computed weighted average mean and median using the same variable of the dataset and received 19.81 and 20.3, respectively.
References
- Descriptive Statistic, By Prof. Shalabh, Dept. of Mathematics and Statistics, IIT Kanpur.
![]()
