In the previous note on the descriptive statistic, we have seen graphical ways to visualize the association of variables using 2d scatter plots, Quantile-Quantile plots, and 2d kernel density estimates. The major problem using graphical tools is that when the data values are in a higher dimensional, the relationship may not be visual as the data points would be overlapped each other. The second problem is that we can not quantify it mathematically.
In this note, we will see a statistical-based analysis technique called Pearson’s correlation coefficient, one of the methods to measure the degree of association between the continuous variables. However, there are other methods to calculate the correlation coefficient, such as Spearman and Kendall, specifically to find the relationship between ordinal variables. The result will display the strength and direction of the relationship.
The above techniques are well suitable when we are dealing with bivariate correlations. Nevertheless, there are others, such as correlations or measurements of distance or dissimilarity of intervals, or counts using Euclidean distance, Euclidean squared, Chebyshev, Block, Minkovsky, etc.
Note: It is helpful to measure the relationship only when the variables possess a linear relationship. It implies that if the relationship is non-linear, then the correlation coefficient should not be used.
Understanding of Data Type
To measure the degree of a linear relationship between two variables, we have different analytical tools, and the selection of these tools is based on the variable’s nature. The variable can be quantitative and qualitative. In quantitative, it can be either discrete or continuous. Whereas in qualitative, it can be either categorical, ordinal, etc. A few of the popular available tools are correlation coefficient, rank coefficient, contingency tables, chi square coefficient, and so on.
The most crucial part is understanding variable data types, and as we know, based on that, we select the appropriate analytical tool. In the below section, we will learn and understand to identify different data types.
Continuous Variables
- The number of hours of study affects the marks obtained in an examination.
- Electricity consumption increases when the weather temperature rises. In this example also, variable takes decimal values too.
- The weight of infants and small children increases as their height increases under normal circumstances.
In all the above examples, the associated variables are continuous in nature and can take numeric values—That’s why the above examples are considered a continuous variable. For example, the obtained marks can be 50, 60, 60.50, 60.25, etc.
Discrete and counting Variables
- We want to know whether male students prefer mathematics over female students.
- We want to know if the vaccine given to the person was effective or not.
These observations are based on counting and the two variables are discrete and counting.
Ordinal Variables (Ranked data)
- Two judges give ranks to a fashion model.
- Two persons give ranks to food prepared or their scores are ranked.
These observations are the ranks of two variables (two judges). For example, 1st, 2nd, 3rd positions, etc.
Understanding of Correlation
At the very first, we will understand the concept of correlation and the association between two variables. The association can be linear or non-linear. However, the correlation is a statistical tool to study only the linear relationship between two variables. It is explained in the below section.
Let us consider two continuous variables, X & Y, assuming that two variables possess a linear relationship in the form of Y = a + bX, where a and b are unknown constant values. The possible relationship between two variables can be positively, negatively, or no correlation. This is illustrated with the help of the below diagram.

Two variables are correlated if the change in one variable results in a corresponding change in the other variable. Suppose two variables deviate in the same direction. In that case, i.e., the increase or decrease in one variable results in a corresponding increase or decrease in the other. The correlation is positive, or variables are said to be positively correlated.
Two variables deviate in the opposite direction, i.e., as one variable increases, the other decreases, and vice versa, the correlation is said to be negative, or the variables are said to be negatively correlated.
No correlation
One variable changes and the other remains constant on average, or there is no change in the other variable. The variables are said to be independent, or they do not correlate.
We understood the concept of correlation, and now we need to define a mathematical quantity that can measure it. And for this, we have a statistical tool called correlation coefficient based on variance and covariance. Mainly, variance measures the variability of a variable as an average squared deviation of individual data points from the arithmetic mean. Whereas the covariance measures the covariability of variables.
Karl Pearson Coefficient of Correlation
Let us consider two continuous variables, x, and y, which have n data points on each variable, and it is represented in pairs as  . The
. The 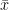 and
and 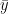 are the arithmetic mean of x and y variables which is computed as
are the arithmetic mean of x and y variables which is computed as  and
and  respectively.
respectively.
The variance of x and y are represented as var(x), and var(y) and computed as  and
and  respectively.
respectively.
The covariance of x and y are represented as cov(x,y) and computed as  . If we further expand the covariance equation, then we will get as
. If we further expand the covariance equation, then we will get as  .
.
 =
= 
= 
r measures the degree of linear relationship. It is also called as Bravis-Pearson Correlation Coefficient or Product Moment Correlation Coefficient.
Note: Correlation Coefficient should not be used to measure the degree of non-linear relationship. So the better approach is first to confirm that the relationship is linear then use this measure.
Interpretation of Karl Pearson Coefficient of Correlation
In general, the range of r lies between -1 and 1, and the value of r tells whether the correlation is positive (0 to 1], negative [-1 to 0), or no correlation (0).
- r > 0 indicates a positive association between x and y, or in other words, it says that x and y are positively correlated.
- r < 0 shows a negative association between x and y, or in other words, it says that x and y are negatively correlated.
- r = 0 indicates no association between x and y, and x and y are uncorrelated.

Value of r has two components – sign and magnitude. The sign of r indicates the nature of association and it is explained as follows:
- The positive sign of r indicates a positive correlation. As one variable increases, another variable also increases. Similarly, as one variable decreases, another variable also decreases.
- The negative sign of r indicates a negative correlation. As one variable increases, another variable decrease. Similarly, as one variable decreases, another increase. It shows the opposite relationship between the two variables.
The magnitude of r indicates the degree of linear relationship.
- r = 1 implies perfect positive linear relationship whereas r = 0 represents no correlation. Any other value of r between 0 and 1 indicates the degree of a positive linear relationship.
- r = -1 indicates perfect negative linear relationship whereas r = 0 represents no correlation. Any other value of r between -1 and 0 indicates the degree of a negative linear relationship.
The value of r close to zero indicates that the variables are independent, or the other possibility is that the relationship is nonlinear. It means, if the relationship between x and y is nonlinear, then the degree of the linear relationship may have a lower value or be close to zero. So when x and y are independent, the r value is zero, but it is not conversely true.
Assumptions of Karl Pearson’s Correlation Coefficient
- Observations should be in pairs and filled with the continuous data type.
- Variables should not contain outliers.
- Measure the relationship should possess a linear relationship.
Properties of Karl Pearson’s Correlation Coefficient
- The correlation coefficient is symmetric, it means, r(x,y) = r(y,x). For example, the correlation coefficient between height and weight is the same as that between weight and height.
- The correlation coefficient is independent of units of measurement of x and y. For example, one person measures height in meters and weight in kilograms. And another person measures height in centimeters and weight in grams. The correlation coefficient would be the same.
References
- Descriptive Statistic, By Prof. Shalabh, Dept. of Mathematics and Statistics, IIT Kanpur.
![]()
