TF-IDF, or Term Frequency–Inverse Document Frequency, is a statistical measure widely used in Natural Language Processing (NLP) and Information Retrieval to evaluate the importance of a word in a document relative to a collection or corpus of documents. Unlike simple word frequency counts, TF-IDF balances the occurrence of common and rare words, highlighting terms that are most meaningful for distinguishing documents within a corpus.
Introduction
In any collection of documents, some words (like “the”, “is”, “and”) appear frequently but carry little unique meaning. Simply counting word frequency (term frequency, or TF) can overemphasize such common words. Conversely, rare words may be more informative but are underrepresented by raw counts. TF-IDF addresses this by combining two metrics:
- Term Frequency (TF): Measures how often a word appears in a document.
- Inverse Document Frequency (IDF): Measures how unique or rare a word is across the entire corpus.
The product of these two values, TF × IDF, gives the TF-IDF score, which increases with the frequency of a word in a document but is offset by how common the word is in the corpus.
Term Frequency (TF)
Term Frequency quantifies the frequency of a word in a document. It is typically normalized to prevent bias towards longer documents. For example: If “car” appears 25 times in a document of 1,000 words: 
Inverse Document Frequency (IDF)
Inverse Document Frequency measures how unique or rare a word is across the corpus.
Where:
 = Total number of documents
= Total number of documents- = Number of documents containing term
- Example: If “car” appears in 300 out of 15,000 documents:
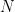 = Total number of documents
= Total number of documents = Number of documents containing term
= Number of documents containing term 

TF-IDF Score
The TF-IDF score for a term in a document is simply:
- Example: For “car” with and : .
 and
and  :
:  .
.Step-by-Step Example
Suppose we have three documents:
- Doc 1: “The cat sat on the mat.”
- Doc 2: “The dog played in the park.”
- Doc 3: “Cats and dogs are great pets.”
Let’s calculate the TF-IDF for the term “cat”:
- TF Calculation:
- In Doc 1: “cat” appears once in 6 words →
- In Doc 2: “cat” appears 0 times →
- In Doc 3: “cat” (or “cats”) appears once in 6 words →
- In Doc 1: “cat” appears once in 6 words →
- IDF Calculation:
- “cat” appears in 2 out of 3 documents.
- TF-IDF Calculation:
- Doc 1:
- Doc 2:
- Doc 3:
- Doc 1:





This shows “cat” is somewhat important in Docs 1 and 3, but not in Doc 2.
Why Use TF-IDF?
- Identifying Important Terms
- TF-IDF helps extract keywords and relevant terms from documents, improving information retrieval and search engine performance.
- Filtering Common Words
- Words that appear in almost all documents (like “the”, “and”) get very low IDF scores, reducing their impact on document similarity and classification.
- Highlighting Unique Terms
- Rare words that appear in only a few documents get higher IDF scores, making them more influential in distinguishing those documents.
Applications
- Search Engines: Ranking documents based on query relevance.
- Text Mining: Extracting features for machine learning models.
- Document Clustering: Grouping similar documents.
- Spam Detection: Identifying unusual or suspicious terms.
- Document Summarization: Highlighting key concepts.
Limitations
- Context Ignorance: TF-IDF does not consider semantics or word order; “cat sat” and “sat cat” are treated the same.
- Synonyms: Words with similar meanings but different spellings are not linked.
- Sparsity: Large vocabularies can lead to high-dimensional, sparse vectors.
- Static Weights: Scores are fixed once calculated; they do not adapt to new documents unless the entire corpus is reprocessed.
Implementation in Python
from sklearn.feature_extraction.text import TfidfVectorizer corpus = [ "the cat sat on the mat", "the dog played in the park", "cats and dogs are great pets" ] vectorizer = TfidfVectorizer() tfidf_matrix = vectorizer.fit_transform(corpus) print(vectorizer.get_feature_names_out()) print(tfidf_matrix.toarray())
This produces a matrix where each row represents a document and each column a term, with values as TF-IDF scores.
| Term | Doc 1 TF | Doc 2 TF | Doc 3 TF | IDF | Doc 1 TF-IDF | Doc 2 TF-IDF | Doc 3 TF-IDF |
|---|---|---|---|---|---|---|---|
| cat | 0.167 | 0 | 0.167 | 0.176 | 0.029 | 0 | 0.029 |
| the | High | High | Low | Low | Low | Low | Low |
| mat | 0.167 | 0 | 0 | High | High | 0 | 0 |
TF-IDF remains a cornerstone technique in text analysis, providing a simple yet powerful way to quantify the importance of words in documents. By balancing local (TF) and global (IDF) term significance, it underpins many modern applications in search, text mining, and machine learning pipelines.
TF-IDF with N-grams
from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pd
# Sample corpus
corpus = [
"I love machine learning",
"Machine learning is fun",
"I enjoy coding and learning",
"Coding is fun and exciting"
]
# Initialize TF-IDF Vectorizer (unigrams and bigrams)
vectorizer = TfidfVectorizer(ngram_range=(1, 2), stop_words='english')
# Compute TF-IDF
tfidf_matrix = vectorizer.fit_transform(corpus)
# Get feature names
feature_names = vectorizer.get_feature_names_out()
# Create DataFrame
tfidf_df = pd.DataFrame(tfidf_matrix.toarray(), columns=feature_names)
# Output
print("Corpus:")
for i, doc in enumerate(corpus):
print(f"Document {i+1}: {doc}")
print("\nTF-IDF Scores:")
print(tfidf_df)
print("\nVocabulary:")
print(feature_names)
As a output:

Why Use Logarithm in Inverse Document Frequency (IDF)?
The logarithm function plays a crucial role in the calculation of the Inverse Document Frequency (IDF) component of TF-IDF, ensuring the measure is stable, meaningful, and effective. Here are the main reasons for applying the log in IDF:
- Controls Large Values
- Problem: Rare terms that appear in very few documents (e.g., only one document) cause the raw IDF value to become extremely large.
- Example: For a corpus with documents, if a term appears in only one document (), the raw IDF is:Such a large value can disproportionately dominate the TF-IDF score.
- Solution: Applying the logarithm compresses this large value:This compression prevents rare terms from overwhelming the scoring system.
 documents, if a term appears in only one document (
documents, if a term appears in only one document ( ), the raw IDF is:Such a large value can disproportionately dominate the TF-IDF score.
), the raw IDF is:Such a large value can disproportionately dominate the TF-IDF score.- Smooths Frequency Variations
- Term frequencies vary widely across the corpus; some terms appear in nearly every document, others in very few.
- Without log scaling, the IDF values would span a huge range.
- For very common terms where , the ratio , and:This means common terms receive an IDF close to zero, reflecting their low usefulness in distinguishing documents.
 , the ratio
, the ratio  , and:This means common terms receive an IDF close to zero, reflecting their low usefulness in distinguishing documents.
, and:This means common terms receive an IDF close to zero, reflecting their low usefulness in distinguishing documents.- Scalability to Large Corpora
- In massive datasets, raw IDF values can become unreasonably large.
- Example: For documents and a term appearing in documents:
- Applying log reduces this to:
- This ensures term weights grow at a sensible rate even as the corpus size increases.
 documents and a term appearing in
documents and a term appearing in  documents:
documents:- Information-Theoretic Justification
- The log in IDF is inspired by information theory, where rarer events carry more information (higher “surprise”).
- Logarithmic scaling reflects this intuition by assigning higher weights to rare terms but in a gradual, principled manner rather than abruptly.
- This aligns with the concept of entropy and information content.
- Empirical Effectiveness
- Log-based IDF has been validated through extensive use in:
- Search engines
- Document classification
- Clustering and information retrieval
- It consistently improves the quality of retrieval and classification results in real-world applications.
- Conclusion
Using the logarithm in IDF is more than a technical trick; it is a mathematically sound and empirically proven approach that:
- Prevents extreme inflation of weights for rare terms
- Fairly reflects the rarity and discriminative power of terms
- Enhances the stability and effectiveness of TF-IDF in ranking and retrieval tasks
Without the log transformation, TF-IDF scores would be unstable, overly sensitive to outliers, and less useful for practical NLP and information retrieval applications.
Usecase: BM25 Lucene Algorithm (BM25Similarity)
Overview
BM25 (Best Matching 25) is a ranking function widely used in information retrieval systems to estimate the relevance of documents to a search query. Lucene, a popular open-source search library, uses BM25 as its default similarity algorithm for scoring and ranking documents.
BM25 improves upon traditional TF-IDF by incorporating term frequency saturation and document length normalization, making search results more relevant and balanced.
Key Components of BM25 in Lucene
- Term Frequency (TF) Saturation
BM25 models the impact of term frequency with diminishing returns: after a certain point, additional occurrences of a term contribute less to the document’s relevance score. This prevents documents from gaining unfair advantage simply by repeating a term excessively. - Inverse Document Frequency (IDF)
Reflects how informative a term is by considering its rarity across the entire corpus. Rare terms have higher IDF scores, increasing their impact on relevance. - Document Length Normalization
BM25 normalizes scores based on the length of the document relative to the average document length in the corpus. This adjustment prevents longer documents from dominating rankings just because they contain more terms.
BM25 Formula in Lucene
The BM25 score for a term  in document
in document 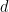 is computed as:
is computed as:
Where:
- = frequency of term in document
- = length of document (number of terms)
- = average document length in the corpus
- = term frequency saturation parameter (default ~1.2)
- = length normalization parameter (default ~0.75)
- = inverse document frequency of term
 = frequency of term
= frequency of term  = length of document
= length of document  = average document length in the corpus
= average document length in the corpus = inverse document frequency of term
= inverse document frequency of term Advantages of BM25 in Lucene
- More Relevant Results: Balances term frequency and document length for better ranking accuracy.
- Flexibility: Parameters can be tuned for specific datasets or search requirements.
- Efficiency: Suitable for large-scale search applications with fast scoring.
- Widely Adopted: BM25 is the default in Lucene and Elasticsearch, reflecting its effectiveness.
Practical Usage and Extensions
- BM25 is often combined with other techniques like query expansion or semantic search for enhanced retrieval.
- Lucene allows subclassing BM25Similarity for advanced customizations.
- Hybrid search systems leverage BM25 for keyword relevance alongside embedding-based semantic models.
Summary
| Aspect | Description |
| Algorithm Type | Probabilistic ranking function |
| Core Components | Term frequency saturation, IDF, length normalization |
| Parameters |  (TF saturation), (TF saturation),  (length normalization) (length normalization) |
| Default Values in Lucene |  , ,  |
| Use Case | Document ranking in search engines and IR systems |
| Customization | Adjustable parameters, subclassing for fine-tuning |
Weighted Word2Vec with TF-IDF
Weighted Word2Vec with TF-IDF is a technique that enhances document or sentence representations by combining pretrained word embeddings (Word2Vec vectors) with TF-IDF weights. Instead of treating all words equally, this method weights each word’s embedding by its TF-IDF score before aggregating, producing a more meaningful and discriminative vector for the entire document.
Conceptual Overview
- Word2Vec embeddings: Provide dense vector representations for words capturing semantic similarity.
- TF-IDF weights: Reflect the importance of each word in a document relative to the whole corpus, emphasizing rare but meaningful words and downplaying common ones.
- Weighted aggregation: Multiply each word vector by its TF-IDF weight, then sum or average these weighted vectors to obtain a document-level embedding.
This approach addresses the limitation of simple averaging of word embeddings, which treats all words equally and may dilute the impact of important words.
Mathematical Formulation
Let:
- = number of documents
- = vocabulary size
- = embedding dimension
- = TF-IDF matrix (each row is a document’s TF-IDF vector)
- = word embedding matrix (each row is a word’s embedding)
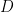 = number of documents
= number of documents = vocabulary size
= vocabulary size = embedding dimension
= embedding dimension = TF-IDF matrix (each row is a document’s TF-IDF vector)
= TF-IDF matrix (each row is a document’s TF-IDF vector) = word embedding matrix (each row is a word’s embedding)
= word embedding matrix (each row is a word’s embedding)The weighted document embeddings matrix  is:
is:
Each document vector is the weighted sum of its word embeddings, weighted by TF-IDF.
Implementation Outline
- Preprocessing:
- Clean and tokenize documents.
- Remove stopwords, punctuation, and extremely rare or frequent words.
- Lemmatize tokens for normalization.
- Calculate TF-IDF:
- Use a TF-IDF model to generate a sparse matrix of shape (documents × vocabulary size).
- Each entry represents the TF-IDF weight of a word in a document.
- Load Word Embeddings:
- Use pretrained embeddings (e.g., GloVe, Word2Vec).
- Extract embeddings for each word in the vocabulary, forming a matrix (vocabulary size × embedding dimension).
- Compute Weighted Document Vectors:
- Multiply the TF-IDF matrix by the embedding matrix.
- Result is a dense matrix (documents × embedding dimension), where each row is the weighted embedding of a document.
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
from gensim.models import KeyedVectors
# Sample documents
docs = ["the cat sat on the mat", "the dog barked at the cat", "cats and dogs are friends"]
# 1. Calculate TF-IDF matrix
vectorizer = TfidfVectorizer()
tfidf_matrix = vectorizer.fit_transform(docs)
vocab = vectorizer.get_feature_names_out()
# 2. Load pretrained embeddings (example: GloVe or Word2Vec)
# model = KeyedVectors.load_word2vec_format('path_to_model', binary=True)
# For demonstration, create random embeddings for vocab words
embedding_dim = 100
embedding_matrix = np.random.rand(len(vocab), embedding_dim)
# 3. Compute weighted document embeddings
doc_embeddings = tfidf_matrix.dot(embedding_matrix) # shape: (num_docs, embedding_dim)
print("Document embeddings shape:", doc_embeddings.shape)
Advantages
- Improved document representation: Highlights important words via TF-IDF weighting.
- Semantic richness: Leverages pretrained embeddings capturing word meaning.
- Simple and efficient: Matrix multiplication is fast and scales well.
Summary
Weighted Word2Vec with TF-IDF combines the strengths of statistical weighting and semantic embeddings. It produces document vectors that are both contextually meaningful and sensitive to word importance, leading to better performance in many NLP tasks.
References
- Applied Natural Language Processing. Prof. Ramaseshan Ramachandran. Department of Computer Science and Engineering. Chennai Mathematical Institute, Madras.
CITE THIS AS:
“NLP – Understanding TF-IDF” From NotePub.io – Publish & Share Note! https://notepub.io/notes/artificial-intelligence/speech-and-language-processing/natural-language-processing/nlp-term-frequency-inverse-document-frequency/
![]()
