Median is one of the techniques to measure the central tendency of data. It divides the observations into two equal parts. At least fifty percent of the values are greater than or equal to the median, and the remaining values are less than or equal to the median.
Median in Descriptive Statistics
In simple words, the median is a measure that tries to divide the total frequency into two parts. For example, If we say that the median of our frequency distribution is 100. It means, 50% of the values are greater than or equal to 100, and the remaining values are equal to or less than 100.
It is a better measure than the arithmetic mean in the case of extreme observations or outliers. Let us first undestand how the extreme observations or outlies affect the mean and median values.
- Suppose we have three observations [2,4,6], and its average mean value is equal to (2+4+6)/3 = 4, and the median is 4. However, suppose one of the observations has altered, and now it is [2,4,100]. So its average mean value is equal to (2+4+100)/3 = 35.3, whereas the median remains the same. We can understand that if there are extreme values or observations, the average mean value changes drastically, but the median stays the same.
We will learn, understand and compute the median for grouped and ungrouped data using python programming language on the tips dataset.
Median (ungrouped data)
The calculation of the median for the ungrouped data (discrete variable) is very straightforward. Let us consider we have 




Case 1: When
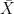
![X \left [ \dfrac{n+1}{2} \right ]](https://s0.wp.com/latex.php?latex=+X+%5Cleft+%5B+%5Cdfrac%7Bn%2B1%7D%7B2%7D+%5Cright+%5D+&bg=ffffff&fg=000&s=0&c=20201002)
For example: Suppose there are a total of
Case 2: When
![\left [ \dfrac{X \left [ \dfrac{n}{2} \right ] + X \left [ \dfrac{n+2}{2} \right ] }{2} \right ]](https://s0.wp.com/latex.php?latex=%5Cleft+%5B+%5Cdfrac%7BX+%5Cleft+%5B+%5Cdfrac%7Bn%7D%7B2%7D+%5Cright+%5D+%2B+X+%5Cleft+%5B+%5Cdfrac%7Bn%2B2%7D%7B2%7D+%5Cright+%5D+%7D%7B2%7D+%5Cright+%5D+&bg=ffffff&fg=000&s=0&c=20201002)
For example: Suppose there are a total of
Compute Median for ungrouped data using Python
# Observation List
x = [11, 13, 12, 14, 15, 17, 16]
# Find the lenght of a given list.
x_len = len(x)
# Sort the observations in ascending order.
x.sort()
# Calculate Median
# Two cases
# Find whether total number of observations are even or odd using modulo operator.
if x_len%2 == 0:
# 1st case, when total number of observations are even.
x_med = (x[int(x_len/2)-1] + x[int((x_len+2)/2)-1])/2
else:
# 2nd case, when total number of observations are odd
x_med = x[int((x_len+1)/2)-1]
print(x_med)
In the above code, we have used python list data type to store observations and calculate the median without using standard python library functions.
Median (grouped data)
Whenever we have a group data or observations from any continuous variable, then the first step is that we try to create the frequency table, and it consists of classes with the assumption that each class are equally distributed.
Suppose there are k classes such as 
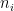
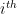
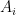


Where:
is a lower limit of
is a width (upper limit – lower limit) of
is a relative frequency of
is a relative frequency of
Compute Median for grouped data using Python
import seaborn as sns
import pandas as pd
import numpy as df
import math
import matplotlib.pyplot as plt
# Load tips dataset from seaborn package
tips_data = sns.load_dataset('tips')
max_bill_amount = int(math.ceil(tips_data['total_bill'].max()))
interval_len = int(math.ceil(max_bill_amount/10))
sum_of_total_bills = tips_data['total_bill'].sum()
# Create a class interval automatically
total_bins = [i for i in range(0,max_bill_amount+interval_len,interval_len)]
total_bills_groupby_interval = pd.cut(x=tips_data['total_bill'], bins=total_bins)
# Calculate absolute frequency
absolute_frequency_table = tips_data.groupby(total_bills_groupby_interval)['total_bill'].count()
# Renaming headers and put into dataframe
frequency_table = pd.DataFrame({'Class Interval':absolute_frequency_table.index, 'Absolute Frequency':absolute_frequency_table.values})
# Calculate Relative Frequency
frequency_table["Relative Frequency"] = frequency_table['Absolute Frequency']/frequency_table['Absolute Frequency'].sum()
# To calculate median class
# Find whether total number of observations are even or odd using modulo operator.
x_len = absolute_frequency_table.sum()
if x_len%2 == 0:
# 1st case, when total number of observations are even.
x_med = (x_len/2 + (x_len+2)/2)/2
else:
# 2nd case, when total number of observations are odd
x_med = (x_len+1)/2
# Median Class interval
# Calculate Cummulative Frequency
median_of_class_interval_index = 0;
for index in frequency_table.index:
abs_val = frequency_table['Absolute Frequency'][index]
if index == 0:
cum_val = 0
else:
cum_val = frequency_table["Cumulative Frequency"][index-1]
frequency_table.at[index, "Cumulative Frequency"] = cum_val + abs_val
if index > 0:
if frequency_table["Cumulative Frequency"][index] >= x_med and x_med > frequency_table["Cumulative Frequency"][index-1]:
median_of_class_interval_index = index
# Calculation of median
left = frequency_table['Class Interval'].apply(lambda x: x.left).astype(float)
e_m_1 = left[median_of_class_interval_index]
d_m = interval_len
f_m = frequency_table["Relative Frequency"][median_of_class_interval_index]
sum_f_m_1 = 0
for index in range(0,median_of_class_interval_index-1):
sum_f_m_1 += frequency_table["Relative Frequency"][index]
# Formula to calculate median
median = e_m_1 + (d_m/f_m) * (0.5 - sum_f_m_1)
print("Median {:.1f}".format(median))
frequency_table
In the above code, we computed the median using the formula mentioned in the median for grouped data section. If we compare mean and median values, we can conclude that using the same dataset, the weighted mean value was 19.81, whereas the median value is 20.3. We can very well observe that both the estimates produce a slightly different result.

References
- Descriptive Statistic, By Prof. Shalabh, Dept. of Mathematics and Statistics, IIT Kanpur.
324 total views, 1 views today
